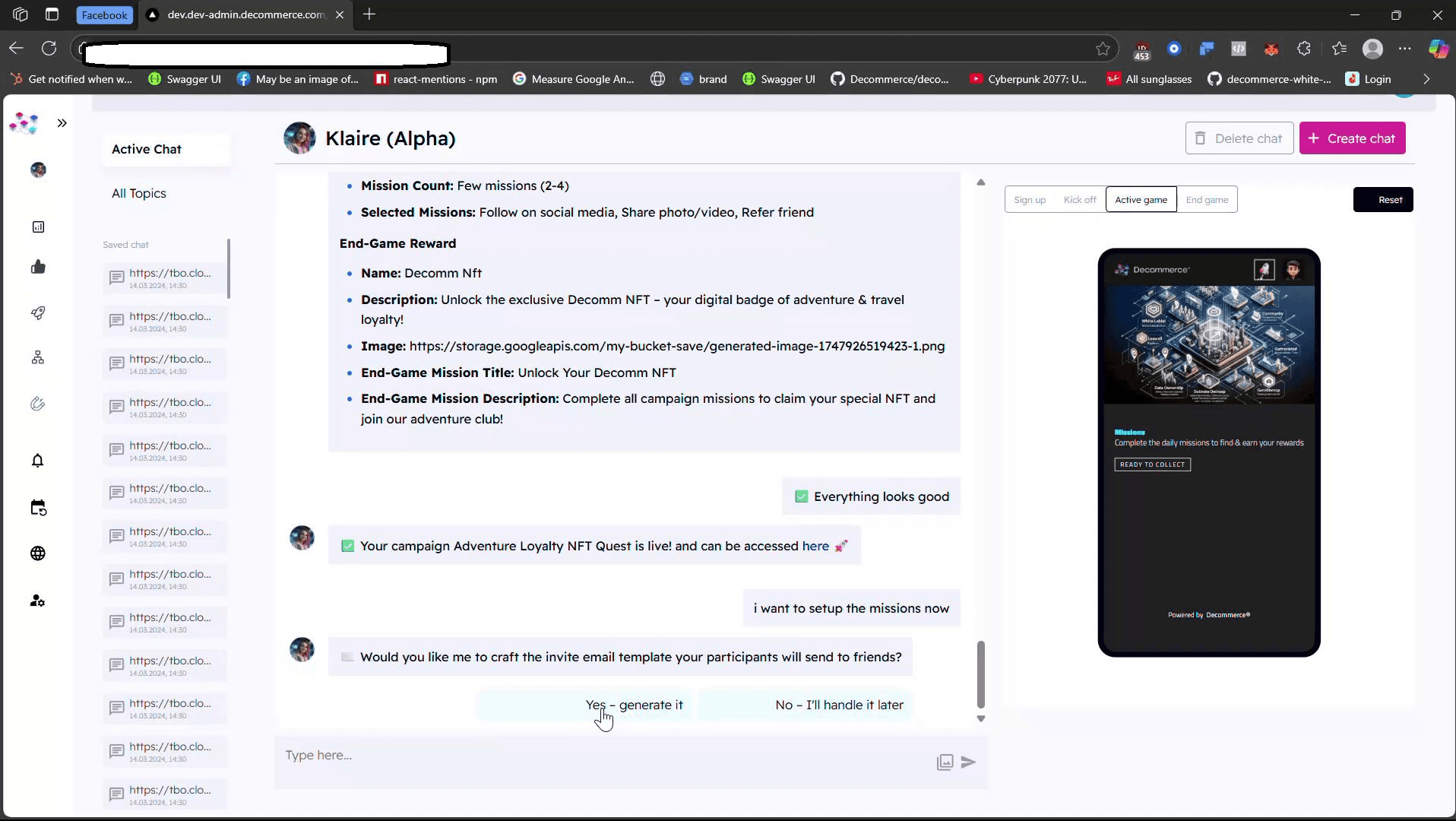
A few months ago I built a fully automated B2B outbound pipeline in n8n. Input: a company name in a Google Sheet. Output: a personalised email draft sitting in Gmail, ready for a human to glance at and send. Zero manual work in between.
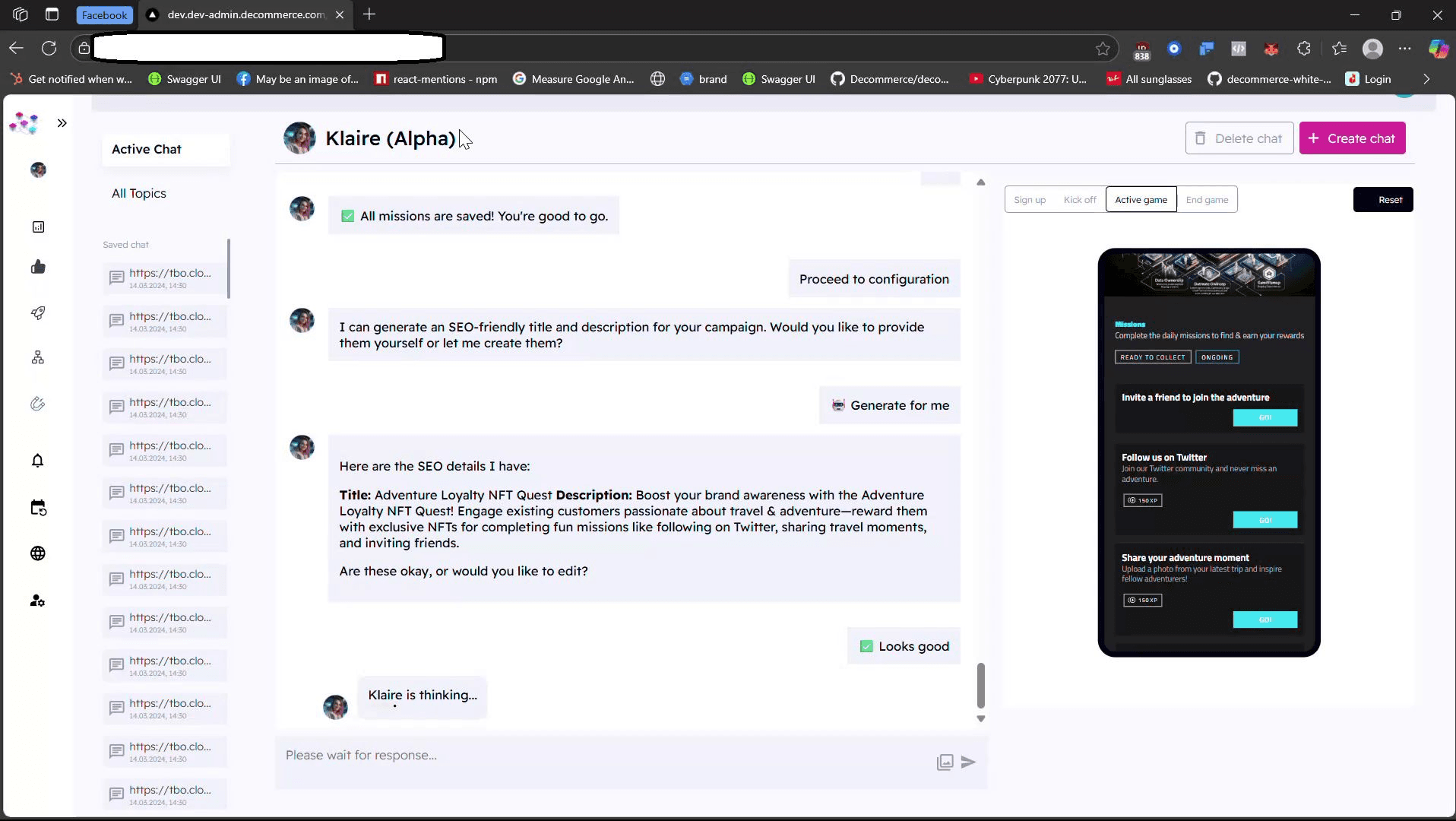
The pipeline runs six connected workflows. Apollo finds the right contact. Claude scores the matches and picks the target. PhantomBuster scrapes LinkedIn activity. Google Custom Search pulls public signals. Claude builds an intelligence profile, drafts a cold email, and writes the Gmail draft. A second workflow handles follow-ups — day two tries a Vapi AI phone call first and only falls back to email if unanswered, day five sends a concise second touch. A third polls Gmail every minute, classifies replies, updates the sheet. A fourth deduplicates so no lead ever gets emailed twice.
None of that is the hard part. Connecting APIs is plumbing. n8n makes plumbing trivial.
The hard part is making AI decisions reliable enough to trust without checking every single output. A classifier that's 92% accurate sounds great until you realise that 8% failure rate means dozens of bad labels a week on a pipeline doing thousands of runs. An LLM-written email that's good 19 times out of 20 still embarrasses you on the twentieth if nobody reads it.
The answer isn't one trick, it's a layered one. Strict schemas on every LLM output so bad data fails loud instead of silent. Tool calling for anything that touches a database, so the model proposes and the code disposes. Validation gates between stages that refuse to move forward on malformed input. And one human-in-the-loop checkpoint at the point of irreversibility — the Gmail send button — because that's the exact place where a human's skim costs you seconds and catches the 5% the model got wrong.
Self-hosted on GCP, because cloud n8n hits limits fast on a pipeline moving this much volume. 6,316 executions in a week. Instead of a rep reaching five qualified leads a day, the system reaches a hundred.
That's the real engineering problem in AI automation: not whether the model can do the task, but how you build a system that catches the model when it can't.